Squid Log Parsing for Proxy Billing
Parsing logs from Squid is a routine task for us, we perform this task on a regular basis (currently hourly) to bill our customers for used traffic. The process involves a script on our central server connecting to each remote server in turn, rotating the logs on that machine, then pulling the old one down to the local system. The system silently ignores servers that are down, we’re already kept up to date about outages by Nagios. The script will warn if it’s able to connect, but anything goes awry (permission errors, premature disconnect, etc.) By rotating the logs using a central script, rather than doing it automatically on each machine, the case of a log being rotated, but not transferred back to the central server (due to a down or unreachable server) is mitigated.
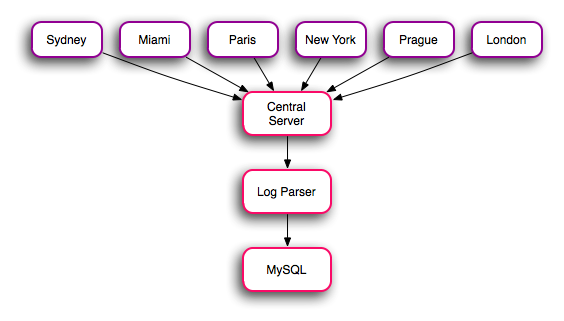
The log parser is called with a single parameter, the path to the log in question, from that it determines the name of the server from which the logs originated. The system where most of the scripts are largely oblivious to the source of their data has allowed us to expand our network significantly without any changes to the scripts (the most recent change was moving from a 4 hour rotation cycle to a 1 hour cycle). The logs we receive from squid look like this:
1294011828.214 1309 184.163.123.123 TCP_MISS/200 10032 GET http://wonderproxyblog.com/ paul DIRECT/76.74.254.120 text/html
1294011828.414 581 184.163.123.123 TCP_MISS/404 5564 GET http://wonderproxyblog.com/.well-known/host-meta paul DIRECT/72.233.2.58 text/html
1294011828.784 0 184.163.123.123 TCP_MEM_HIT/200 943 GET http://s0.wp.com/wp-content/themes/h4/global.css? paul NONE/- text/css
1294011828.787 0 184.163.123.123 TCP_MEM_HIT/200 791 GET http://s2.wp.com/wp-includes/js/l10n.js? paul NONE/- application/x-javascript
1294011828.795 0 184.163.123.123 TCP_HIT/200 9024 GET http://s.gravatar.com/js/gprofiles.js? paul NONE/- text/javascript
1294011828.858 66 184.163.123.123 TCP_MISS/200 2158 GET http://b.scorecardresearch.com/beacon.js paul DIRECT/96.17.156.19 application/x-javascript
1294011828.871 0 184.163.123.123 TCP_MEM_HIT/200 1511 GET https://ssl-stats.wordpress.com/w.js? paul NONE/- application/x-javascript
1294011828.928 139 184.163.123.123 TCP_MISS/200 2749 GET http://edge.quantserve.com/quant.js paul DIRECT/64.94.107.11 application/x-javascript
1294011828.997 205 184.163.123.123 TCP_HIT/200 27230 GET http://s1.wp.com/wp-includes/js/jquery/jquery.js? paul NONE/- application/x-javascript
1294011829.091 334 184.163.123.123 TCP_MISS/200 414 GET http://wordpress.com/remote-login.php? paul DIRECT/74.200.247.60 text/html
We then parse that output with a regular expression (regex):
(?P<timestamp>\d+)\.\d{3}\s+-?\d+ (?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) (?P<cache>\w+)\/(?P<httpresponse>\d+) (?P<size>\d+)
(?P<uri>.+) (?P<user>\S+) (?P<method>[A-Z]+\/\S+).+!\n
The regular expression names its parameters, giving us an easy set of data to work with inside our billing script. The regex isn’t perfect, the system occasionally runs into a line it doesn’t parse properly which it emails back in a report. Originally this happened frequently, so the regex was tweaked (inside the RxToolkit of Komodo IDE), it’s now quite rare. As you can see there’s an incredibly large number of lines for just a partial page load (me loading the blog front page), it doesn’t include the numerous requests required to populate a google map widget from a recent post, or any of the images used on the page. We don’t require this level of granularity for billing, nor do we necessarily want it to be easily accessible. To turn this into a slightly more manageable log entry we merge requests: All requests through a given proxy server, for a given hour, are merged into a single piece of data to be inserted into the database containing: the user’s ID, the user’s account number, the server ID (from our network), the traffic in bytes, and the timestamp of the hour. This gives us a more manageable usage table, the raw log files are merged with other files from the same server on the same day and archived. While we’d like to just get rid of them (they’re just gathering dust and occupying hard drive space) many jurisdictions require record keeping from providers, and we’d like to be able to fully account for usage for our customers upon request.
To come back to the log file for a moment, I’d like to look at one piece of data in particular:
1294011828.871 0 184.163.123.123 TCP_MEM_HIT/200 1511 GET https://ssl-stats.wordpress.com/w.js? paul NONE/- application/x-javascript
1294011828.928 139 184.163.123.123 TCP_MISS/200 2749 GET http://edge.quantserve.com/quant.js paul DIRECT/64.94.107.11 application/x-javascript
1294011828.997 205 184.163.123.123 TCP_HIT/200 27230 GET http://s1.wp.com/wp-includes/js/jquery/jquery.js? paul NONE/- application/x-javascript
What our regular expression terms cache, the squid docs term Squid Result Codes and it generally indicates where squid got the resource. In the case of a miss it had to retrieve the resource from the URL in question. A TCP_HIT indicates it was cached, while a TCP_MEM_HIT indicates it was in cache, and still in memory avoiding hitting the disk. In our experience the list from the squid docs is non-exhaustive, for example TCP_REFRESH_UNMODIFIED doesn’t appear, so some research or testing was necessary as we put the system into use. We use this information to determine whether to record the size at its original value, or to double it (as a server proxying a 100Kb resource must download it from the source server, then upload it to the end user).
We’ve considered technologies like Spread to give us near real time logs from across the network, but we haven’t really seen the need. None of our customers are asking for it, and the need to go read old log files for detailed information has only come up twice, both times well after the fact.