Moving Ping Data to S3 & Athena
We've been running our global ping statistics for years. Every hour we have every server on our network ping every other server, and record that data in MySQL. In fact, generating these ping stats led to one of our first blog posts. But as our network has grown, so has the burden of keeping all that data around – currently ~1B rows or ~30GB of data with ~15GB of indexes.
"So you have a lot of data", you say. Indeed we do! And it's affecting us in a few ways:
- Our nightly backup is full, not incremental. So every night we're backing up that 30GB, which means that
- Backups take hours (wall time)
- Backups use considerable I/O for those hours
- We're using & paying for a fair amount of space in S3 & Backblaze for data that hasn't changed, in some cases for years.
- Attempts to use the data can take hours (it's indexed for the exact way we use it on the site, nothing else)
- Using the data can block inserts, which makes other things really grumpy.
So we wanted to reduce the burden on our systems without deleting the interesting ping data. It seemed like there must be a good cloud solution for this, but we weren't quite sure what it was. I asked my followers on twitter, and we received two great suggestions: AWS with Simple Storage Service (S3) & Athena, and Google Big Query. The two products looked to offer similar solutions. We're already using S3 in our backup system, so that's the direction we went.
S3 & Athena
These tools are pretty great. S3 allows you to upload arbitrary files to buckets. These files can be private, public, or managed through complicated Access Control Lists (ACLs. We use them for backups and for our global screenshot service, ShotSherpa. Amazon's Athena allows you to upload files to S3 as CSV, json, apache common log, etc. files, then query those files as if they were a well-indexed database. It's kind of magic really.
Uploading to S3
We decided to shard our data into CSV files by date (e.g. 2016-01-01.csv). We originally considered grouping data by month (2016-01.csv) which would have given us far fewer files, but would have either: A) had us overwriting the current month's data every day, or B) left us unable to access this month's data in Athena.
To do the upload, we bit the bullet and let MySQL index the timestamp column for a few hours, then got our export together, which resembled the following:
mysql -u export -e "SELECT * from network_pings WHERE timestamp >= '2015-01-01' AND timestamp < '2015-01-02' INTO OUTFILE '/var/lib/mysql-files/2015-01-01.csv' FIELDS TERMINATED BY ',' ENCLOSED BY '' LINES TERMINATED BY '\n' ;" wonderproxy
The export file is then ready to be uploaded to S3, we use the incredibly handy s3cmd.
s3cmd put ./2015-01-01.csv s3://wn-ping-data/2015-01-01.csv
s3cmd uploads the file to s3 and deletes the local file. To upload all of our legacy data, we scripted the export.
Setting Up Athena
Using Athena is remarkably similar to using any regular SQL system: first you define tables, and then you can query the data. The only difference from normal SQL workflows is that you never insert data.
Defining the tables was a bit of a pain: I found the AWS documentation on the available datatypes hard to use and harder to find (eventually ending up at hive documentation). Eventually I was able to define my table in the same form as it exists locally.
CREATE EXTERNAL TABLE `pings`(
`source` int,
`destination` int,
`timestamp` timestamp,
`min` double,
`avg` double,
`max` double,
`mdev` double)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://ping-datas/'
TBLPROPERTIES (
'has_encrypted_data'='false'
)
Migrating Old Data
We had a few years of data to migrate and didn't want to babysit the process. Bash to the rescue!
#!/bin/bash
BEGIN='2017-04-12'
for i in `seq 0 19`
do
DATE_START=`date --date="$BEGIN +$i days" +%Y-%m-%d`
DATE_STOP=`date --date="$DATE_START +1 days" +%Y-%m-%d`
echo $DATE_START $DATE_STOP
S3CONF=/etc/backup/s3cfg
OUTFILE="/var/lib/mysql-files/$DATE_START.csv"
BUCKET="s3://wn-ping-data/$DATE_START.csv"
mysql --defaults-file=/etc/mysql/debian.cnf -e "SELECT * from network_pings WHERE timestamp >= '$DATE_START' AND timestamp < '$DATE_STOP' INTO OUTFILE '$OUTFILE' FIELDS TERMINATED BY ',' ENCLOSED BY '' LINES TERMINATED BY '\n' ;" wonderproxy
s3cmd -c $S3CONF put $OUTFILE $BUCKET
rm $OUTFILE
done
A day's migration took about 6 minutes. Surprisingly, the script took a little less time as it got closer to the present: more data, but easier for MySQL to find I guess.
Problems
We ran into a number of problems along the way:
- After a year's data had been migrated, I attempted to delete it from our MySQL database. This deletion took ~24 hours and the background process to clean up from such a long running transaction took just over a day. This was more than 48 hours of a overloaded MySQL I hadn't planned for with a "quick delete".
- Creating the index on
timestampwhile data was being inserted led to insertion of new ping data slowing down considerably, nearly exhausting available connections. - After the disastrous attempt to delete one year, we were afraid to delete more. We ended up creating a new table, copying some data over, renaming everything, then dropping the old table. The drop table took ~3 minutes to run, blocking all other queries while it ran. Still better than 2 days of MySQL load warnings, but rather inelegant.
The end
We're incredibly happy with how things stand now:
- Nightly backups take ~6hours less than they used to. Compare:
Before
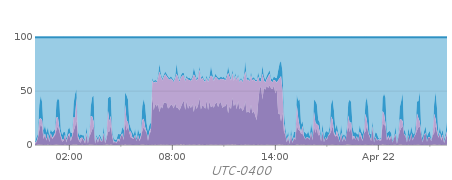
After
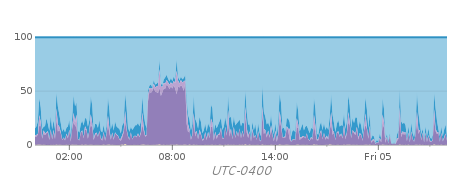
- Access to the ping data locally is faster. Pages like the ping between Toronto & Sydney load much faster.
- We're able to access our ping data.
select count(*) from pings;
1,048,048,968
select ssource.name, sdest.name, min(min) as min, avg(avg) avg, max(max) as max, avg(mdev) as mdev from pings
inner join servers ssource on pings.source = ssource.id
inner join servers sdest on pings.destination = sdest.id
group by (ssource.name, sdest.name);
| name | name | min | avg | max | mdev |
|---|---|---|---|---|---|
| SanFrancisco | Austin | 44.332 | 50.56974071 | 2093.89 | 0.757902704 |
| Piscataway | Chisinau | 114.048 | 127.0578771 | 2278.05 | 1.605722278 |
| Nuremberg | Bratislava | 9.754 | 11.25562384 | 205.314 | 0.227628895 |
| Riga | Bratislava | 32.566 | 52.74259325 | 680.427 | 0.534945375 |
| Seattle | Bratislava | 151.186 | 159.0907507 | 559.066 | 0.630765144 |
| Dubai | Chisinau | 135.195 | 173.2585131 | 1371.19 | 3.707562773 |
| Auckland | Chisinau | 303.612 | 321.8982936 | 4853.89 | 5.742768056 |
| Belfast | Bratislava | 37.796 | 41.39520064 | 134.44 | 0.278373601 |
| Bismarck | Bratislava | 133.264 | 168.1607224 | 701.64 | 4.207793405 |
| Frosinone | Chisinau | 60.5 | 74.98497252 | 413.314 | 0.892113415 |
| Lyon | Austin | 111.802 | 121.489948 | 327.727 | 2.699988439 |
| Baltimore | Washington | 2.772 | 8.307516151 | 323.161 | 1.383206588 |
| BuenosAires | Vienna | 233.661 | 265.471438 | 2755.39 | 3.237864982 |
| Mexico | Cincinnati | 41.362 | 72.76548737 | 1643.5 | 2.356069869 |
| Cincinnati | Vienna | 110.519 | 126.1579257 | 1469.55 | 1.646510167 |
| Riga | Seattle | 162.517 | 181.147038 | 586.287 | 1.019970731 |
| Paris | Washington | 76.158 | 86.08202909 | 472.82 | 1.662913123 |
| Louisville | Vienna | 112.905 | 126.9182847 | 4728.98 | 2.165424966 |
Closing Thoughts
We wanted the data off our infrastructure, that was certainly accomplished. During the process we also loaded our MySQL server in new and interesting ways, which led to better monitoring and reporting. We're also reducing our backup cost (ping data is backed up once, not every single night forever), which is nice. As an unexpected bonus we've also managed to make our ping data much more accessible, queries that would take hours now execute in seconds.